Basic z80 opcodes, and a big refactor
In this sprint we’ll be getting the bulk of the z80 opcodes including 16 bit loads, conditional jumps, CALL and RET.
We /bmad-bmm-create-story 4.3 to kick things off. Whilst creating the story the
agent noted that we have a namespace clash: we can’t use C as the “Carry”
conditional word, because C already means “register C”.
What I decided on therefore is to use CS (“carry set”) to indicate the C=1
condition, and we’ll add CC too to keep it symmetrical (both of these
will be familiar to 6502 or ARM assembly programmers). Classic z80 NC is
still available, because that doesn’t clash with anything.
Then I had to take CC out again, because I realised that if BASE is set
to 16 (which it almost certainly will be) then CC is 204 in hexadecimal.
So now it’s CS for C=1 and NC for C=0: not exactly orthogonal, but
hopefully easy to remember.
assembler.asm
All the action’s in here again.
The first fun word is #:
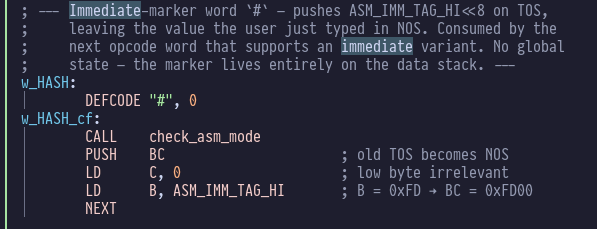
# is a word that marks whatever’s in TOS as an “immediate” constant, for
opcodes that support it, e.g. LD A, 0 would be written as A 0 # LD,.
What happens if we forget the # and type A 0 LD, ? In that case, the
untagged 0 will be treated as the identifier for register B, we’ll effectively
compule LD A, B.
In other words assembly will succeed but produce code that doesn’t work, and ** that’s not acceptable.**
After poking around for a while I realised there are two deficiencies to this design:
- the “forgot #” footgun
- broad range of possible stack values were assigning as tags thanks to using the high byte as a sentinel (0xff, 0xfe, xfd) while only using a handful of the low byte bits to encode registers, conditional flags and labels.
- oh and a third issue is that we can’t properly use the full range of 16 bit immediate constants
I sketched out a more compact coding scheme where the top byte is always 0xFF and everything else is encoded into the bottom byte.
The code review agent wasn’t interested in fixing it: too big a job he said. So
I convened a “party mode” discussion with /bmad-bmm-party-mode and outlined
my concerns.
The “team” kicked around some ideas and made some valid points. We settled on a mildly modified version of the original design. There was a lot of grumbling about “this fix will be as much work as 4.3 was originally!”. So be it!
We invoked BMAD’s “course correction” protocol (you can do this yourself with
/bmad-bmm-course-correction - they’ll try to talk you down) and scheduled a
whole new story 4.3.5 to immediately fix the issues before the next sprint
(extended opcodes) starts.
The outcome is recorded in a Sprint change proposal document. Once approved, the relevant planning
documents are updated, and we can /bmad-bmm-create-story 4.3.5.
It’s an entire sprint of work that we had anticipated, but it’s worth nailing this down now before we get to 4.4 which introduces all the extended opcodes, including all the indexed addressing modes, bit operations, and IO. The old scheme wouldn’t have coped.
Implementation and code review went smoothly, so let’s carry on where we left off.
# looks slightly different:
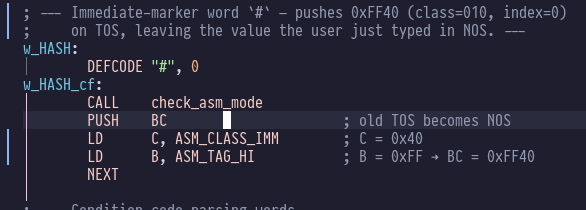
The assembler is now able to warn you if you forget a #:
There are a bunch of new utility routines for our new tag scheme:
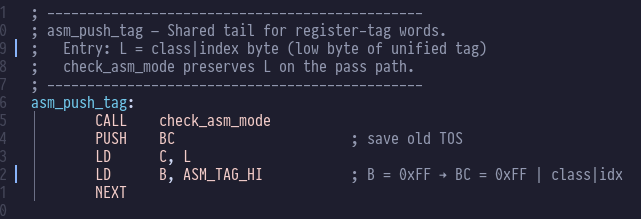

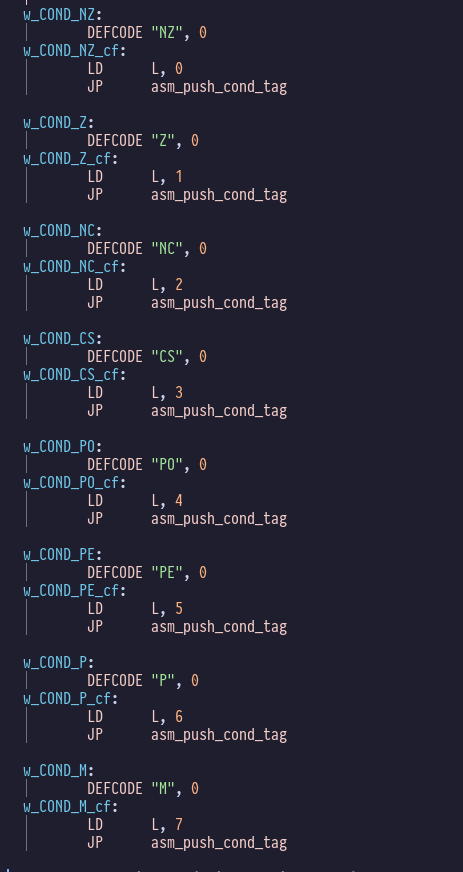
And our condition words get compiled into tags like this:
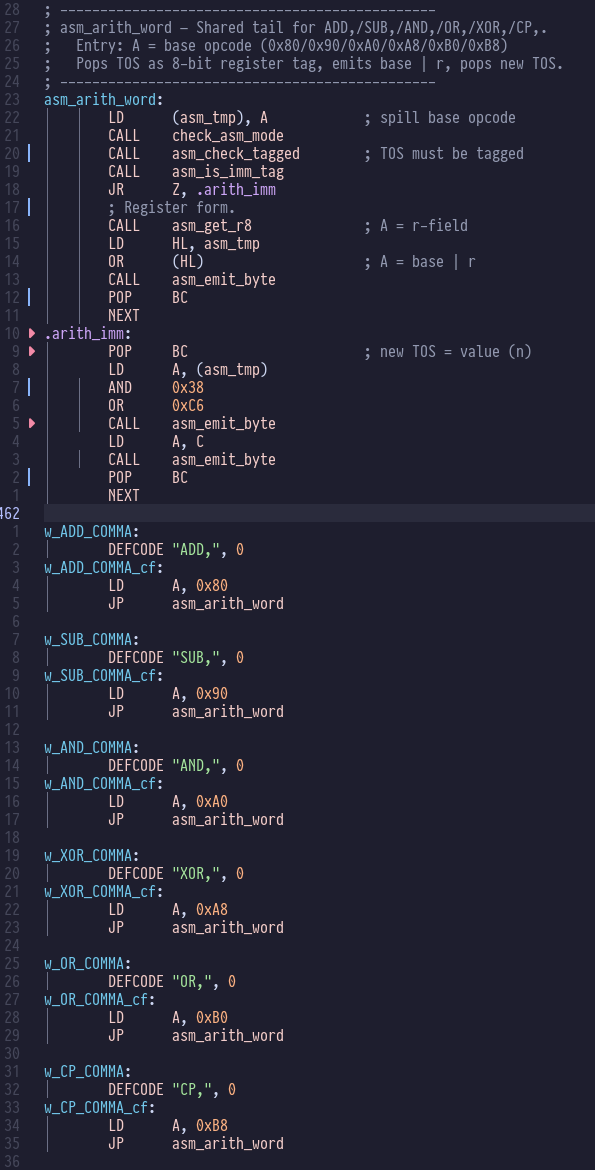
We also gained ADD,, SUB,, AND,, XOR,, OR, and CP, which
all share the same implementation:
RET,, CALL,, JP, and JR, now have full implementations.
The DW and DB words got updated to handle the new tagging
scheme also.
Testing
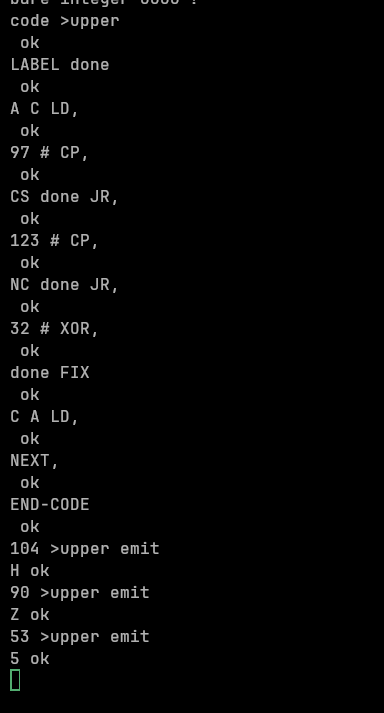
Let’s take it out for a spin! We’ll use our new words to write this definition:
\ >upper — convert ASCII lowercase to uppercase, in Z80 machine code.
CODE >upper ( c -- C )
LABEL done \ forward-reference label (declared before opcodes)
A C LD, \ A = character (low byte of TOS)
97 # CP, \ compare A with 'a'
CS done JR, \ carry set → below 'a', skip conversion
123 # CP, \ compare A with 'z' + 1
NC done JR, \ no carry → above 'z', skip conversion
32 # XOR, \ toggle bit 5: lowercase → uppercase
done FIX \ ← both JR, targets resolve here
C A LD, \ store result back in C (low byte of TOS)
NEXT,
END-CODE
\ Try it:
104 >upper EMIT \ h → H
90 >upper EMIT \ Z → Z (already uppercase)
53 >upper EMIT \ 5 → 5 (not a letter)
And here it is in action: