Labels and data definition words
Not gonna lie, this was the hardest design challenge in AntForth to date. What started as simple whimsy (“just add labels!”) turned out to be quite problematic.
The difficulty is in reconciling the sort of two-pass assembler label behaviour that we’re used to (think sjasmplus) with Forth’s fundamentally single-pass nature, and its almost total lack of syntax (“if it ain’t a number, it’s a word!”).

The initial design used a special L: word to reference a label, and just a
bare word to define the label, a bit like this:
CODE foo
my_label ... some opcodes
... some ore opcodes
my_label L: JP,
I had a few issues with this:
- it’s horribly clunky to write
- it requires patching the outer interpreter (
INTERPRET) so that it recognises new label declarations in asm_mode - any unintentional typos in CODE blocks get promoted to labels, which
never get resolved and cause errors when we hit
END-CODE.
We experimented with using special sigils in INTERPRET to fix point 3.
I think the design was something like a : suffix to declare a label
and an L: prefix to reference a label. Still ugly, and point 2 remains
and that’s the one that really boils my crawfish.
We looked at what previous implementations had done. Some of the
earlier Forths simply avoid the issue by using VALUEs instead of
labels. You declare them and assign HERE to them at the suitable
juncture. Not bad, but I don’t want Forth CFAs intermingled with
my CODE block innards: once I’ve declared CODE it should be pure
z80 opcodes until we hit END-CODE.
The more contemporary CollapseOS has
quite a peculiar assembler architecture, and for labels they
also use the VALUE approach, but with a bunch of special Forth
words for using them as a backwards reference (BR) , forward
reference (FJR) and for setting them LSET.
From the CollapseOS manual:
To avoid using dict memory in compilation targets, we predeclare label variables here, which means we have a limited number of it. We have 3: L1, L2, L3.
You can define your own labels with a simple “0 VALUE lblname”, but you have to do so before you begin spitting opcodes.
It’s better, but it’s still a bit clumsy. But there are some good ideas we can swipe.
In the end, we came up with this:
- a
LABELword that declares a label name, must be start ofCODEblock LABEL foomakesfooa plain-old-Forth word that knows how to handle itself (more later)- to define a label we use a new
FIXword.foo FIXmeans “label foo now points to this memory location” - new words like
fooget cleaned up duringEND-CODEso that the system dictionary isn’t poluted. They are local to thisCODEblock.
The onus is on the user to remember to pre-declare labels and to
FIX them precisely once, but both of these are enforceable by the
interpreter.
I also like that you end up with a mini declarations block at the start of the code block:
CODE someword
LABEL RETRY
LABEL SKIP
RETRY FIX
... opcodes ...
SKIP JR, \ forward ref
... opcodes ...
SKIP FIX \ resolves the JR, above
... opcodes ...
RETRY JP, \ backward ref, already resolved
END-CODE
I am also particularly pleased with the choice of the word FIX:
it has a natural double meaning that fits perfectly.
“Fix this label to the current position” and “fix up any pending
forward references”. Both meanings are simultaneously true whenever
you call it, which is exactly the kind of semantic compression Forth
is all about.
Best of all, we didn’t introduce any hacky nonsense into INTERPRET,
one of the most highly used words in the whole interpreter, avoiding a
guaranteed source of regressions in the future.
After 4 or 5 design iterations, we could finally let development proceed. Code review identified the usual test gaps, and a bunch of copypasta that was quickly refactored.
assembler.asm
LABEL is the big new word in this file. It’s a big routine, so I’m
not going to paste it all here, but here’s the header:
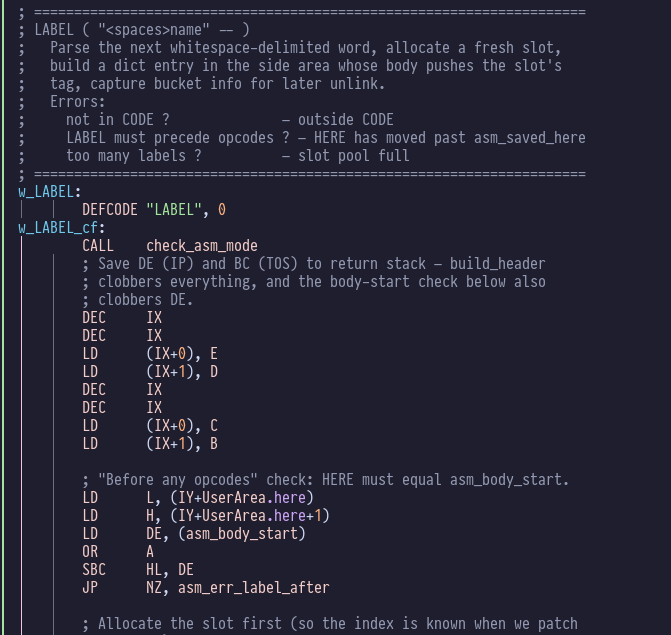
LABEL does a lot of work:
- it creates a “label slot” in the dedicated label sub-dictionary
and temporarily redirects
HEREto point to the new entry - it writes a code body for the new word that will push the word’s “label tag” onto the stack
- it remembers a bunch of dictionary hash bucket state so that it
can unlike itself on
END-CODE - it links its definition into the hash bucket chains so that the
word can be located by
FIND. - it restores
HERE, which hasn’t changed because the system dictionary is unmodified.
FIX is a little more succinct:
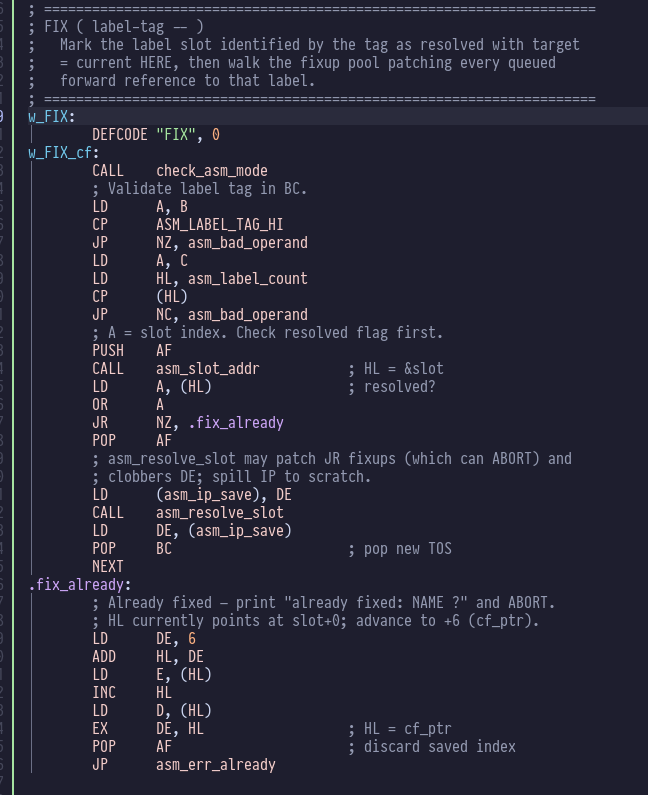
FIX pulls a “label tag” from teh parameter stack (previously
pushed there by the invocation of a label word). It uses the
tag to find the slot for the label, and sets its status to resolved
with an address equal to HERE. If there are any outstanding
“fixups” for the label (a “fixup” is an opcode that referenced the
label before it was FIXed) then those are relocated.
Now’s probably a good time to mention some limitations of our
implementation. Each CODE block:
- can have a maximum of 16 labels
- can have a maximum of 32 fixups
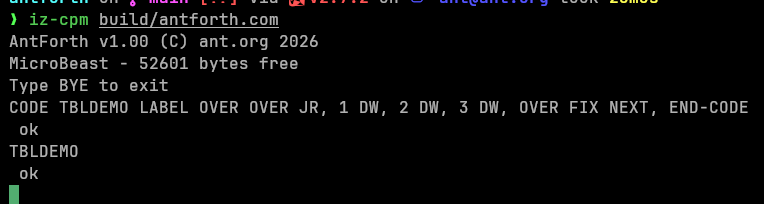
Here’s some example code:
CODE TBLDEMO
LABEL OVER
OVER JR,
1 DW,
2 DW,
3 DW,
OVER FIX
NEXT,
END-CODE
and here it is in action:
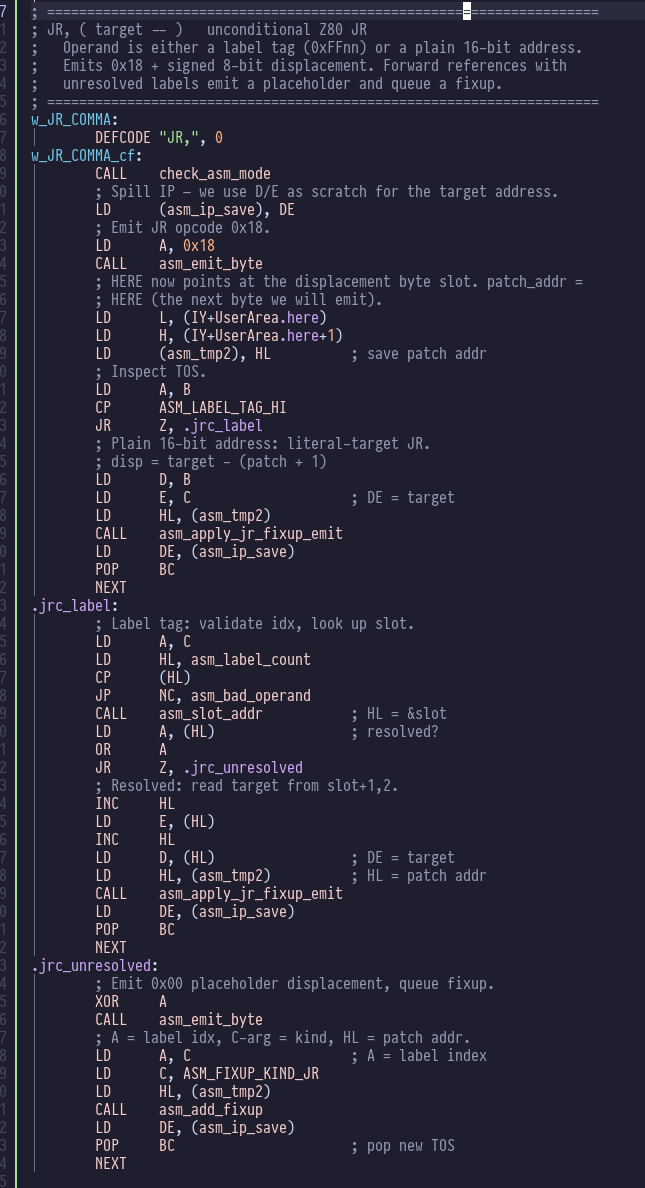
The JR word takes a target off the stack that is either
a label reference or a 16 bit address literal. It emits
the relevant opcode, and if it’s a label reference and the
label is unresolved it queues a “fixup” for when the label
is finally FIXed:
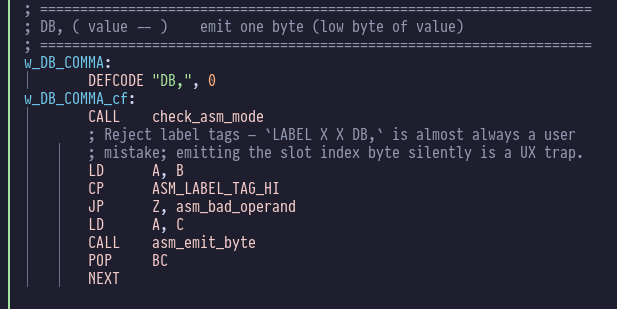
DB is the classic “define a byte”:
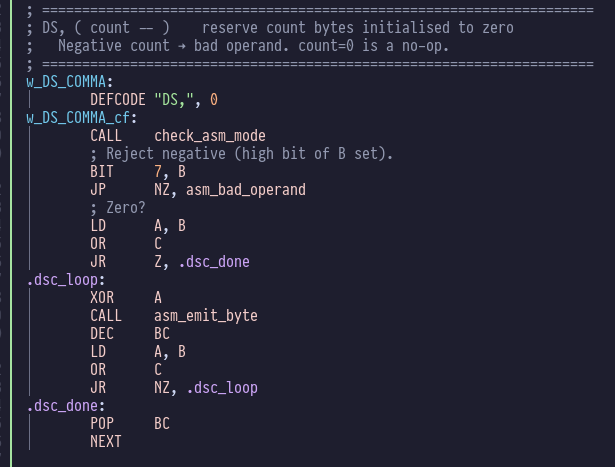
and DS is the classic “define space”:
DW is a little more complex, because unlike DB it will
accept either an immediate constant or a label tag
on the top of the stack, which lets you do things like:
CODE SELFREF
LABEL here_is
here_is DW,
here_is FIX
NEXT,
END-CODE
Of course, the label might be unresolved, in which case a “fixup” for it needs to be queued.
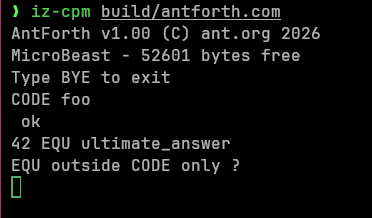
Finally we have the innocuous looking EQU:
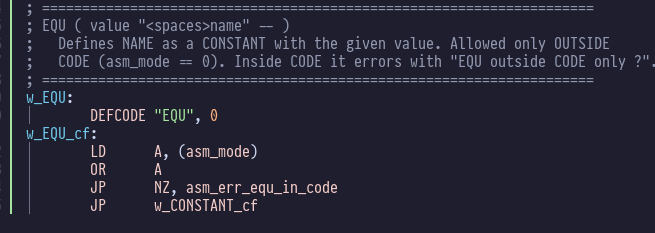
EQU has an important restriction: you can only use it outside
code blocks. You may think I’ve taken leave of my senses, but the
usage is quote manageable:
0x42 EQU PORT-A
0xFE EQU PORT-B
CODE IOTEST
PORT-A DB,
PORT-B DB,
NEXT,
END-CODE
EQUs are still close by, just not in the code block. The reason is,
they are implemented using the standard Forth CONSTANT machinery,
which compiles words, and we don’t want Forth words in the middle
of our pure, unsullied machine code - it’s the same problem that
labels faced, but here we can solve it by simply moving EQUs
(which are constant anyway) out of the CODE block, and then we
don’t need all the intricate side-dictionary/fixup mechanisms
that labels required.
The interpreter will warn you if you forget the rules: