Number formatting and stack inspection
Last time we got the outer interpreter running and we were able to type stuff into it, but we lacked the facility to display any results.
In this sprint, we’ll be building:
.,U.and.Rto let us fetch and view values on the stack.Sto let us view the whole stack non-destructivelyHEXandDECIMALto let us change the current number base
formatting.asm
There are a few helper routines to do with number conversion
and radix bases in here, and then we have the definition of .:
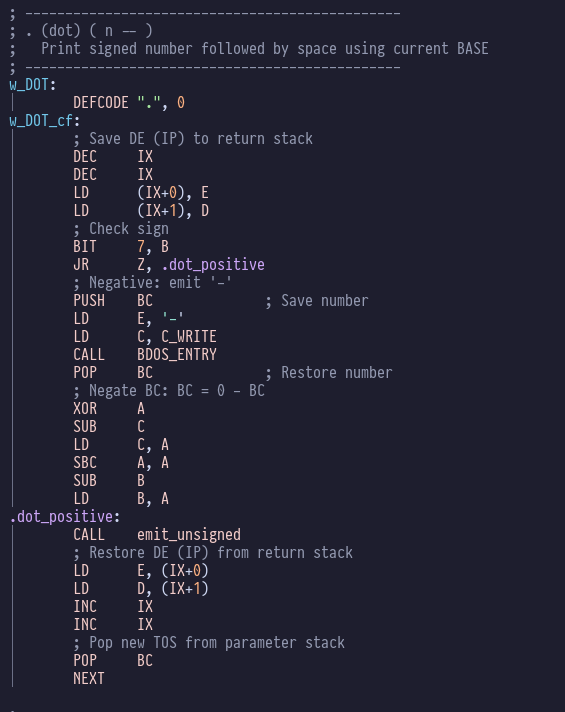
This handles a negative number by emitting a ‘-‘, negating the
number, and falling through to the positive number handling case,
and tath calls emit_unsigned which calls u_to_str which is your
classic integer-to-string conversion that works right-to-left
emitting the remainder after dividing by the radix.
We also have U.:
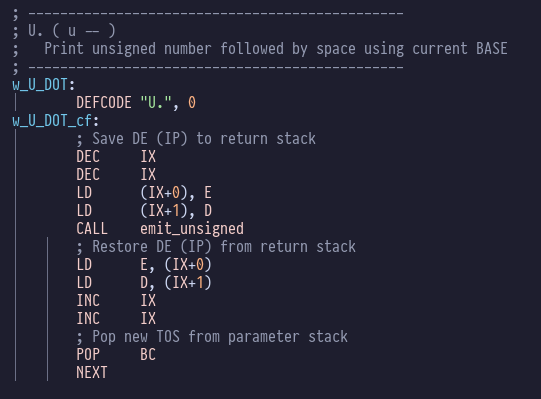
Which doesn’t need to handle negative numbers, so it’s a much
simpler wrapper around emit_unsigned.
The implementation for .R is in here too, but it’s too
long to include in this post.
Likewise .S, which inspects the current contents of the stack
non-destructively, although this did end up raising an interesting
issue - more on this later.
Finally we have the HEX and DECIMAL implementations:
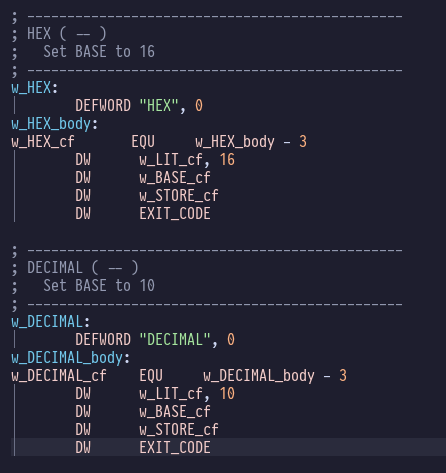
These are proto-Forth, and they couldn’t be much simpler, just leading
the values 16 or 10 respectively into the BASE user variable.
Testing
Both the unit tests and the manual key test still run fine.
I fired up iz-cpm build/antforth.asm eager to try out . and .S
so we could finally see the results of stuff we’d typed in, and I got
this:
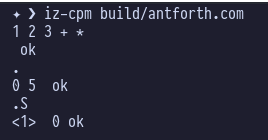
Which looks fine on the surface, but what’s that extra 0 doing on the stack?
The stack should be empty after my final ..
I looked closer:
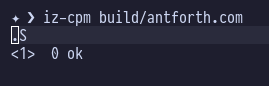
I fired up BMAD, started the developer agent and asked it what was going on. It quickly deduced that the problem was caused by the keeping-Top-of-Stack-in-a-register optimisation that we chose: simply put, the code has no way of knowing whether the value that is in BC is a legitimate entry on the top of the stack, ir just undefined garbage.
The naive way to fix this is to keep a count of the current stack depth, but as we’ve run out of machine registers we’d have to keep this in memory, which means a memory lookup on every stack operation, which kinda defeats the point of the TOS-in-register optimisation anyway.
While searching for better solutions, it quickly became apparent that Claude was trying to gaslight me into accepting that this was perfectly normal and accepted behaviour. Unfortunately for Claude I know that’s not the case, so I called him:

Claude’s bare-faced lies did set me on the right track though: someone must have encountered this issue in Forth’s 50 year history and found an elegant solution.
I discovered the answer, appropriately enough, in comp.lang.forth in a relatively
recent post from 2015:
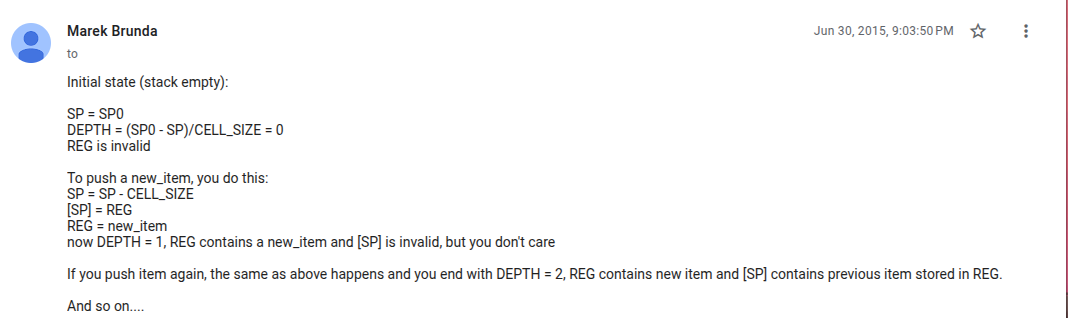
In other words, when you push the first item, you push the garbave BC value onto
the stack, then load BC with the new value. The depth formula is then simply
DEPTH = (S0 - SP) / cell_size where S0 is the base of the stack, an existing
user variable. When the logical depth is 0, SP == S0, and BC is garbage. When
the logical depth is 1, SP == S0 - 2, and BC is value. i.e. depth 0 and depth 1
now have different SP values.
The cost is pushing BC to the stack whenever we push, but we were doing that
anyway so the real cost is just an extra garbage entry on the stack, which we
can now detect and avoid in routines like DEPTH and .S. Pops remain the same,
the final pop will read the original garbage value back into BC and depth will
be zero.
I told Claude Code the good news, and he thought it was a wonderful idea. A short course-correction later, and we were back in business:
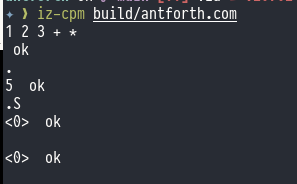
No more bogus zeros on the parameter stack, and another salutary lesson in why you have to keep your wits about you in the AI coding game. Errors like this can compound quickly, and if you were vibe coding this it would be a disaster from this point on (if not much earlier).