Dictionary and hash table
We’re now starting Epic 2, which is all about getting us to a functional AntForth interpreter.
The first story (2.1) is about the dictionary and has table. The dictionary is where all our Forth word definitions are stored, so that they can be looked up when they’re used. Traditionally this is a single-linked list, which is simple to implement but gets slower and slower the more words are added.
We’ve specified that our interpreter should use a more optimised hash-based approach. Effectively we keep 64 separate dictionaries, and decide which dictionary a word belongs to by using some simple mathematical function (the “has function”) on its name.
The hash function needs to be fast and easy to implement on a z80 - we’re using a rotating XOR hash function and 64 mini-dictionaries to meet these needs, but really any function that distributes words across the dictionaries evenly will do.
We’ve already been using this hash lookup approach, but up to now the hashes have been built at assembly time using sjasmplus’ Lua scripting ability.
In this sprint, we’ll be building:
- a z80 native version of the hash function
- the
FINDword, for looking up word names in the dictionary - the
COUNTword, to tell us the length of byte counted strings (like the names of words in the dictionary)
hash.asm
The runtime hashing algorithm is pretty simple:
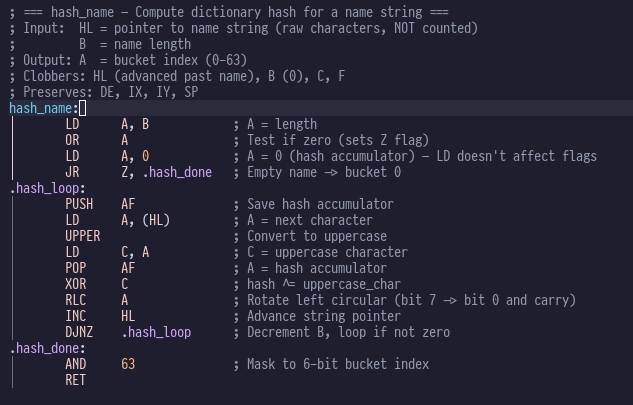
It converts the string to uppercase, XORs the current hash value (initial hash value is
zero) with the uppercase character, and rotates the current hash value left one bit.
Remember that RLC A is an 8 bit rotate as the comment makes clear.
The upper-case conversion code was originally explicit in here, with a whinging comment
about there being duplicate code in dictionary.asm and dire warnings about keeping the
two synchronized - so I asked it to replace all instances of that code with a macro
UPPER.
dictionary.asm
COUNT also gets quite a simple implementation:
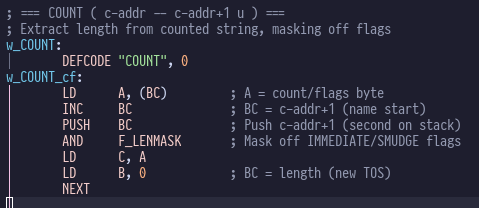
When a word is stored in a forth dictionary, its name is a byte counted string (the string is preceded by a byte that is the count of the number of its characters), but a couple of the top bits of the length byte are used for other purposes, so this routine is basically masking those extra bits out, so we can treat it as a regular byte-counted string.
The implementation of FIND is also here, but it’s a bit too long to include in
this blog post.
In essence what it’s doing is:
- hash the name we’re looking up to identify the relevant dictionary “chain” (mini-dictionary)
- search that chain for a match, searching by length first, then a full name comparison
- if it’s found return the “xt” (execution token) and a +1 or -1 flag depending on whether the word is “immediate” or not (more on this later)
- else return the original address with a zero pushed on top if there was no match.
The FIND routine uses some static storage, so it’s not re-entrant. As we’re
single threaded by design, this shouldn’t be an issue.
Testing
All tests pass, and the manual KEY test still works.