Stack and memory primitives
On to the next BMAD task: 1.3 - stack and memory primitives.
In this sprint, we will acquire the parameter stack manipulation primitives
DUP, DROP, SWAP, OVER, ROT, PICK, ROLL, and DEPTH. We’ll also get the
return stack primitives >R and R> - PUSH and POP operations for the
separate return stack, basically.
We’ll also get ! and @ (16-bit POKE and PEEK) and C! and C@ (their
8-bit equivalents).
If some of the memory operators look oddly familiar, you might be remembering them from BBC BASIC, which took a lot of inspiration from Forth. Another example of this is BBC BASIC’s built-in assembler, more on that later…
Finally we’ll get a few dictionary space allocation primitives: HERE, ALLOT,
, (COMMA), C,, ALIGN, ALIGNED, FILL and MOVE.
Claude will implement tests for each of these, adding them to the current hard-coded test thread in antforth.asm.
Let’s begin! We /bmad-bmm-create-story 1-3, review the story, then
/bmad-bmm-dev-story 1-3, followed by /bmad-bmm-code-review 1-3.
Code review throws up this:
Summary: The implementations look correct based on manual code tracing (DUP through
FILL, plus ROLL for u=0,1,2). The main problem is that 10+ primitives are claimed
as tested (tasks marked [x]) but have no test threads. The highest risk is
MOVE and ROLL — both are complex, both are untested.
Shirking tests is a vibe-coding classic, particularly with Claude. BMM’s multi-layer approach is a good defense against this proclivity though, as demonstrated here. And always run tests manually after every sprint. I told Claude to go ahead and automatically fix those issues.
While that was happening, I researched ROLL a bit further. It’s inclusion here
(and also PICK) is a little odd as its not an ANS Forth core word, but rather
an extension. Furthermore, Forth purists consider these words to be bad practice.
Neither CamelForth nor JonesForth implement them.
Tracing back through or BMAD docs I see these were included early on in FR17 of our Product Requirements Document, so this is a mild human oversight. We don’t technically need them at this stage, but it doesn’t hurt to have these implemented now so I’m not going to take any further action beyond scrutinizing this most complex primitive and making sure it’s well covered by testing later on (when we’ve got a proper interpreter and complicated tests are easier to write).
stack_ops.asm
Before we look at the ROLL implementation, let’s appreciate some of the other stack
primitives:
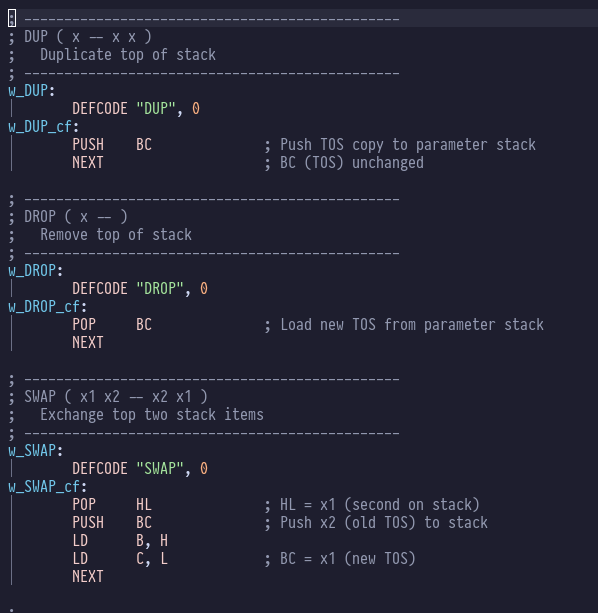
DUP is beautifully simple: the Top-of-Stack is already in BC, so we just need to PUSH BC
to duplicate that onto the top of the z80 stack. Similarly DROP is a simple POP BC -
we remove the top entry in the z80 stack into our top-of-stack register BC, and the
previous value of BC is discarded.
SWAP is equally elegant: get the not-quite-top-of-stack value in HL with a POP, push our
current top-of-stack in BC onto the z80 stack, and then move HL into BC.
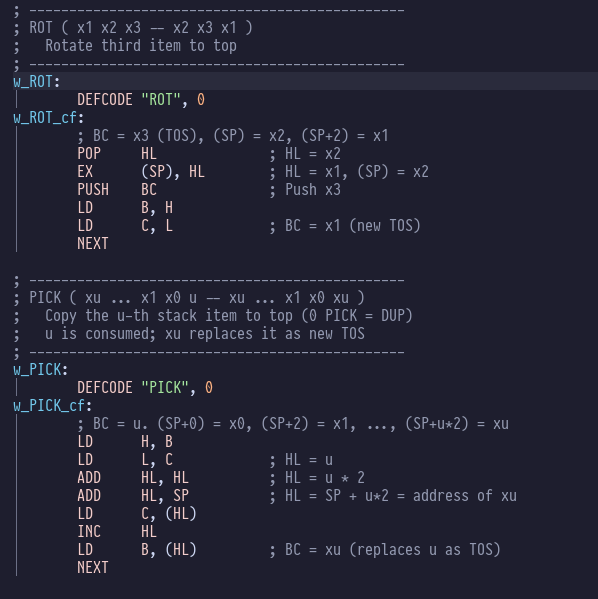
ROT and PICK have equally elegant implementations:
Now let’s look at that implementation for ROLL:
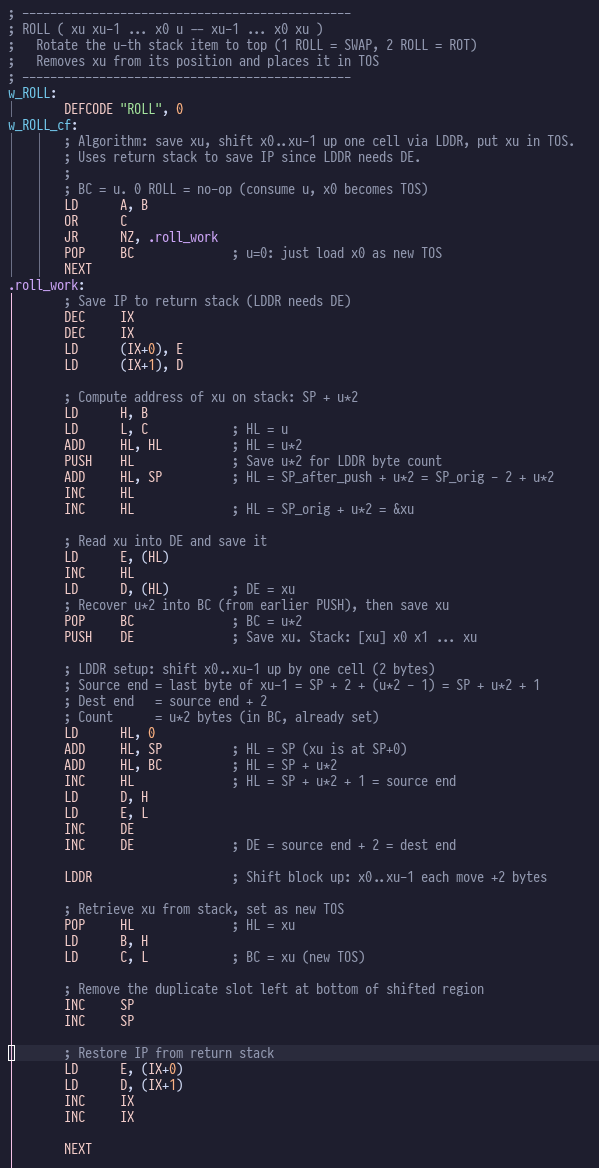
This looks intimidating, but it’s pretty simple: we use the z80’s awesome LDDR to
move a block of memory (the parameter stack) around (think memmove() if you have a
C background), and the rest of it is a lot of fiddling around to get the right
addresses in the right registers.
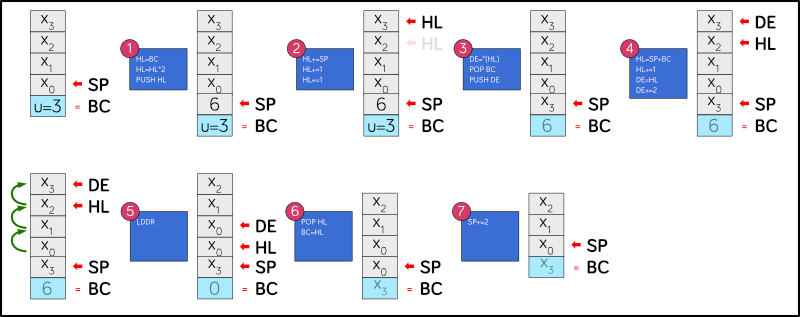
I’ll explain what’s going on with reference to this diagram:
Stack effects
Look at the top of ROLL’s definition and you’ll see this:
; ROLL ( xu xu-1 ... x0 u -- xu-1 ... x0 xu )
The bit in parentheses is called the stack effect and it’s a pithy Forth
commenting convention for showing the state of the stack before we call
ROLL (that’s the left hand bit, before the --) and also the state of
the stack after the call (that’s the right hand bit, after the --).
On each side, the rightmost item is the top-of-stack.
So here was can see that on entry u is on the top of the stack followed byte
u+1 other values that we’re calling xu, xu-1, xu-2, x0 etc. and
on exit xu is on the top of the stack, u is no longer to be seen,
and everything else has shuffled UP one place into the gap that
was xu’s previous location.
So, let’s imagine that we have 4 values x3, x2, x1, x0 on the stack
plus our value for u which is 3 – we want to roll the stack so that
x3 is on top.
The code starts by multiplying u by 2, because 3 16-bit values is
the same as 6 8-bit values, and z80 addressing is all byte based. We
push this count onto the stack, because we’ll need it later when we
do the bulk memory move operation.
Remember, we’re pushing it onto the z80 machine stack, not the Forth parameter stack, where top-of-stack is represented by the BC register, so in effect we’re pushing to position 1 of the Forth parameter stack, BC stays on top.
Once we have that value we add it to the stack pointer to get the
address of x3. But because we just PUSHed something to the stack (the
byte count) that value is now off by 2, so we subtract 2 from HL to
compensate. Now HL points to x3.
Next we load that value into the DE register. Then we POP BC which takes
the byte count off the z80 stack and into the BC register, then we PUSH DE
which means that x3 is now top of the z80 stack (but not top of the Forth
parameter stack, because BC now has the byte count in it).
Next we set up the source and destination addresses for the bulk memory
move. The destination (where we’re going to copy byte to) is always in
DE (DEstination) and the source (where we’re going to copy bytes from)
is always in HL. We get HL by adding the byte count to SP, plus 1 because
we want to start with the second byte of x2. We copy this value to
DE and add 2, so DE now points to the x3 on the bottom of the stack.
Our byte count is already in BC, so when we execute the LDDR instruction,
6 bytes (3 words) get copied from HL to DE.
Once that’s finished the stack is a bit cluttered as we’ve got duplicate
x0 entries from all this shuffling. So we POP HL to x3 from the top of
the z80 machine stack, and move that HL value into BC so now it’s at the
top of the Forth parameter stack also.
Finally we add 2 to SP to ‘erase’ the duplicate x0 value. Then it’s a
bit of housekeeping and the job is finished.
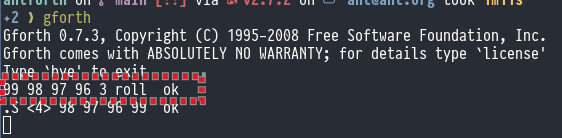
Here’s what ROLL looks like in GForth:
memory.asm
That’s probably enough in-depth analysis for one post, but if you’re
feeling studious there are some equally elegant morsels in memory.asm:
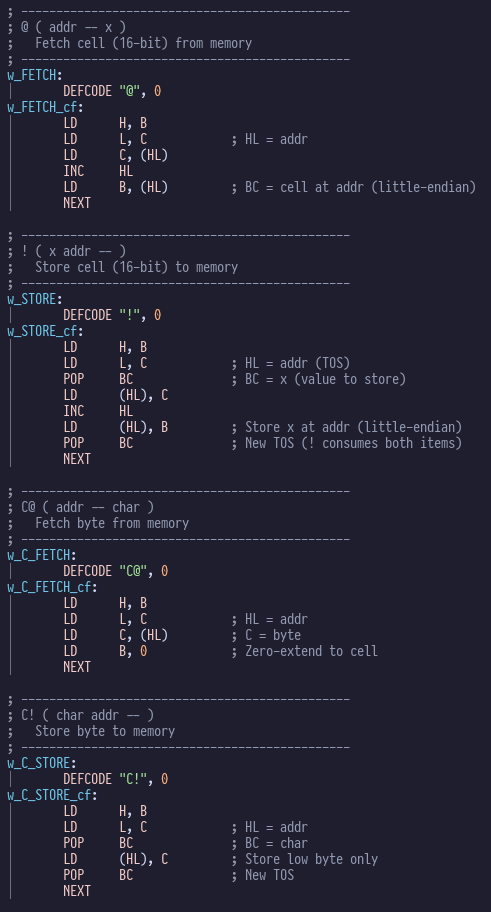
These concise efficient machine code words are the secret behind Forth’s reputation for performance: effectively, it’s just a fancy way of stringing z80 subroutine calls together whilst adding very little overhead.
Testing
To wrap up, we must remain vigilant on the testing front and run the test suite for ourselves.

All looks good: I also checked the code to make sure that I understand what the test thread (in antforth.asm) and that it looks reasonable, and isn’t just returning “everything’s OK, honest!”