Let's see what we got...
Claude has made a basic project scaffold for us, but it’s mostly stub files at this point. What we do have though, is some interesting
stuff going on in macros.asm and inner_interpreter.asm.
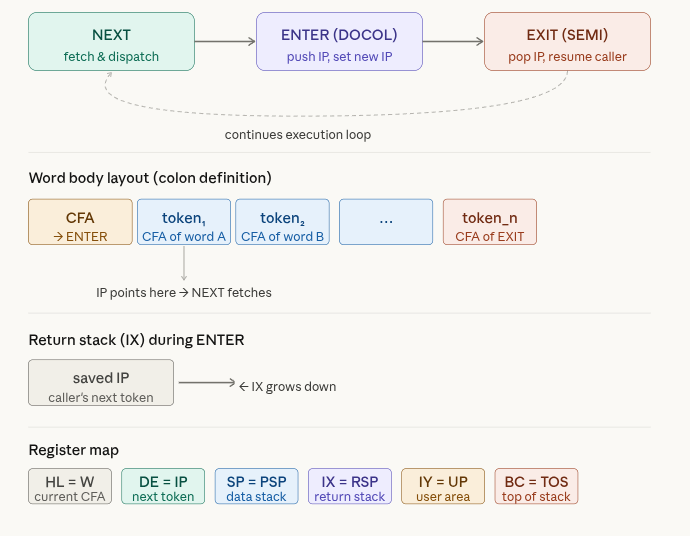
Our register allocation is:
HL= W (working register — points to the current word’s CFA)DE= IP (instruction pointer — points to the next execution token)SP= PSP (parameter/data stack pointer)IX= RSP (return stack pointer)IY= UP (user/task pointer)BC= TOS (top-of-stack cached in register)
In direct-threaded code (DTC), a word’s code field contains the actual machine code address to jump to. For a compiled (colon) word,
this is the address of ENTER (also called DOCOL). For a primitive, the code field is the primitive’s machine code inline.
The three critical routines are NEXT, ENTER, and EXIT.
In macro.asm we have the definition of a crucial macro NEXT, which is what
drives the inner interpreter, moving the execution from one Forth word to the next. NEXT` is the macro/routine
executed at the end of every primitive. It fetches the next execution token (a CFA address) from the thread,
loads it into W (HL), and jumps through it.
Here’s our implementation:
; === NEXT — Inner interpreter fetch-decode-execute ===
; DE = IP, fetch [DE] into HL, advance DE by 2, JP (HL)
MACRO NEXT
EX DE, HL ; HL = IP
LD E, (HL)
INC HL
LD D, (HL)
INC HL
EX DE, HL ; DE = IP+2, HL = code field address
JP (HL)
ENDM
We can compare this with “Case Study 3: Z80” in Moving Forth: part 2 - since this
is where we swiped our register allocation scheme from. Brad Rodriguez gives two slightly different implementations of NEXT for a
direct-threaded interpreter such as ours:
DTC-NEXT: LD A,(DE) (7) (IP)->W, increment IP
LD L,A (4)
INC DE (6)
LD A,(DE) (7)
LD H,A (4)
INC DE (6)
JP (HL) (4) jump to address in W
alternate version (same number of clock cycles):
DTC-NEXT: EX DE,HL (4) (IP)->W, increment IP
NEXT-HL: LD E,(HL) (7)
INC HL (6)
LD D,(HL) (7)
INC HL (6)
EX DE,HL (4)
JP (HL) (4) jump to address in W
We’re loading the next “word” to be executed from where our “instruction pointer” (IP) is pointing, and we’re executing it (by JumPing to it).
The HL register does double duty here: it’s the most flexible z80 register, and here we’re using its ability to do memory load indirection and
an indirect jump. Hence all the EXing so we’re using HL in the right place at the right time.
In direct-threaded code the CFA contains either machine code (for primitives) or a JP DOCOL instruction (for colon words). Jumping through W means primitives run their own body directly.
The rest of macro.asm contains some interesting looking chicanery using sjasmplus’ Lua interpreter. This is to allow us to use macros to
define Forth words whilst using the fancy hash-based dictionary algorithm that we’ve chosen. It all looks terribly exciting, but I wouldn’t
be surprised if this is a source of friction later.
In inner_interpreter.asm is our definition of DOCOL:
; === DOCOL — Enter colon definition ===
; Push IP (DE) onto return stack (IX), set IP to body (following JP DOCOL)
DOCOL:
; Push current IP onto return stack
DEC IX
DEC IX
LD (IX+0), E
LD (IX+1), D
; W (HL) points to code field (the JP DOCOL), body = HL+3
INC HL
INC HL
INC HL
EX DE, HL ; DE = IP = body address
NEXT
We can compare this with the final DTC word ENTER in Moving Forth - part2. Straight away we can see we’ve got an issue: we EX DE,HL and then
call NEXT, and the first thing NEXT does is EX DE, HL so we’ve got a NOP. This is what Brad is hinting with his NEXTHL alternate
entrypoint, and we can ask Claude to make that change too.
First /bmad-agent-bmm-dev to start up a generic dev agent, then we ask him:
❯ in src/inner_interpreter.asm we have a DOCOL macro, this ends with `EX DE, HL: NEXT` and the first line of NEXT (defined in macros.asm) is another `EX DE, HL`. We should have another macro NEXTHL which is the last instructions of NEXT. Then words like DOCOL can skip the `EX DE, HL` and call HLNEXT directly. NEXT can also use NEXTHL.
Then /bmad-bmm-code-review and ask it to review the recent changes. Et voila:
Verdict: Changes are correct and beneficial. The NEXTHL optimization is sound — saves 8 T-states per DOCOL invocation with no behavioral change. No bugs found. Ready to commit.