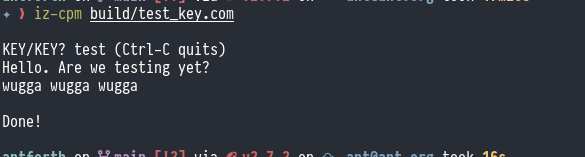
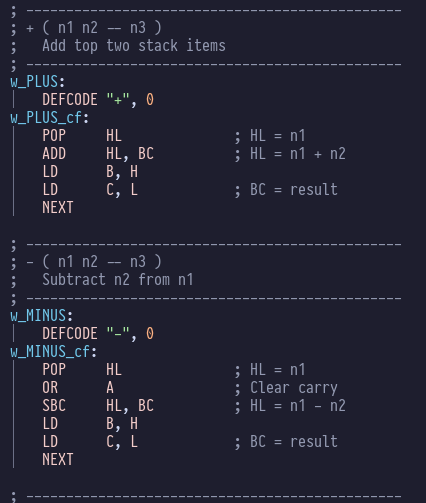
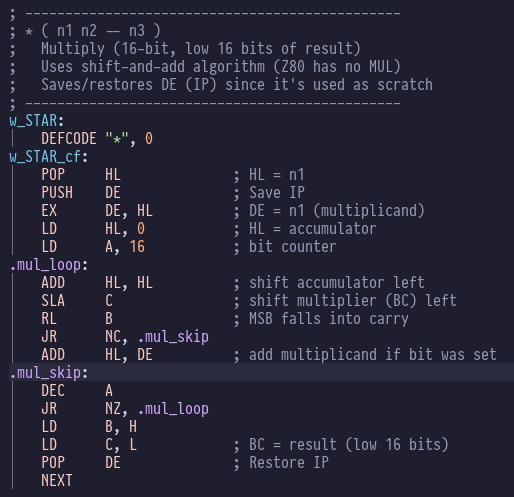
“If you’ve seen one Forth…you’ve seen one Forth” the old joke goes. There’s something about the Forth language
that makes you want to write your own Forth language. Possibly because it attracts the sort of noble pioneers
who relish the challenge of carving out new frontiers from the unyielding bedrock of pure machine code, or possibly
because it attracts the sorts of people who are easily distracted…
A few years ago, whilst learning Rust, I completed (well, ok, 90%) the excellent Exercism.org Rust track.
One of the exercises was a sort of proto-forth interpreter, so that got me thinking. More recently, I bought a
Feersum Technology MicroBeast - a very capable Z80-based retro-computer
with an 8MHz CPU, 512K of RAM and 512K of Flash. This is enormous fun to write code for, and my efforts so far have
involved using modern tooling on my desktop and copying assembled binaries over. But the options for developing
on device are somewhat limited. There’s Microsoft Basic, which devolves into a tangle of GOSUBs before you know it,
and BBC BASIC also runs on the machine, but with a few issues that make it largely unusable. Various other ancient
compilers are available if you want them, can find them, and can make them work.
This is exactly the sort of environment Forth is designed for: bootstrapping your way from nothing to a working REPL
in a relatively small amount of code. So I did the obvious thing, and bought every ancient Forth book I could get my
hands on. There are also some excellent online resources, most notably jonesforth
and Moving Forth - these are monumental resources, worthy of deep
study.
Moving Forth essentially culminates in CamelForth, a modern, ANS-compatible Forth
that can run on a Z80 and that, honestly I could probably have ported in a couple of evenings.
But where’s the fun in that!
AI assisted development
There’s another reason. It’s a divisive one, so bear with me. Like it or not, AI tools are, for the time being, unavoidable.
I was a sceptic for the longest time, but some early experimentation with Gemini, Kimi K2, and GLM convinced me that vibe coding
was genuinely useful: but only up to a point. In surprisingly little time, for all but the smallest projects, you’re left with
an unmaintainable mess, your LLM burning tokens as it oscillates between two complimentary states, neither of which work for
different reasons.
Prompt engineering can get you a little further along, but you spend as much time writing prompts to write code as you would have
done writing the code in the first place.
But there is another way! A chance YouTube video led me to a frame work (SuperClaude, iirc) for a more organised approach, and from there
I migrated to AgentOS, and then finally to The BMAD Method. Essentially, the premise is,
you use old-fashioned structured, engineering methodologies to break work into small chunks that allow your chosen LLM to use
its context effectively, and avoid going off into the weeds. But the beauty is, you use the LLM itself to do all the tedious business
of gathering user requirements, writing briefs, writing project requirements documents, writing an architecture plan, making a sprint plan,
managing epics and stories, writing a test plan, running unit tests, integration tests and regression tests, etc etc.
In short, you get all the rigour, without any of the ball-ache.
I have used this approach in many personal and professional projects, with great success. I have gone from being a John Henry-esque LLM-refusenik
to a slightly rabid born-again evangelist.
How is that fun?
Know thyself says the Temple of Apollo at Delphi. I am aware that prior to the dawn of LLMs the chances of me completing any such
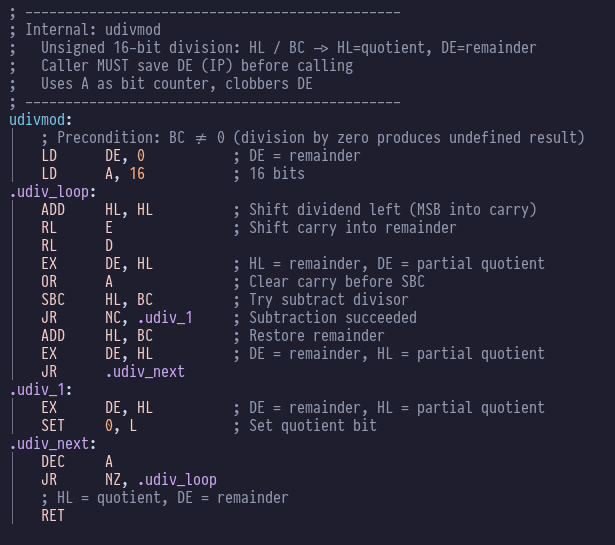
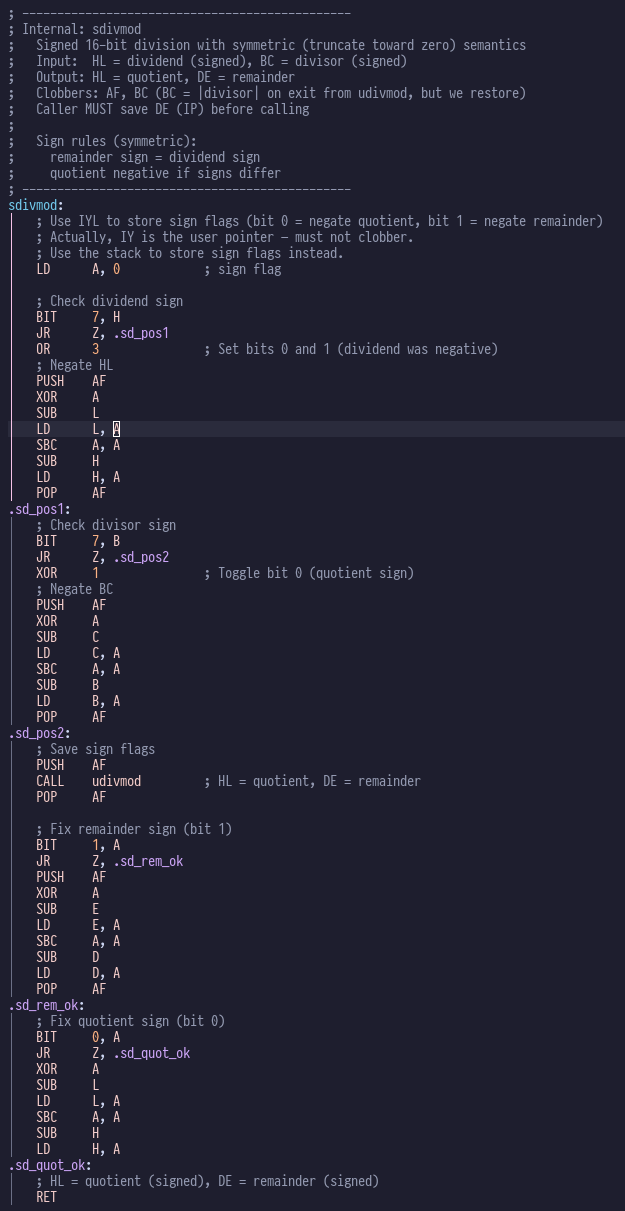
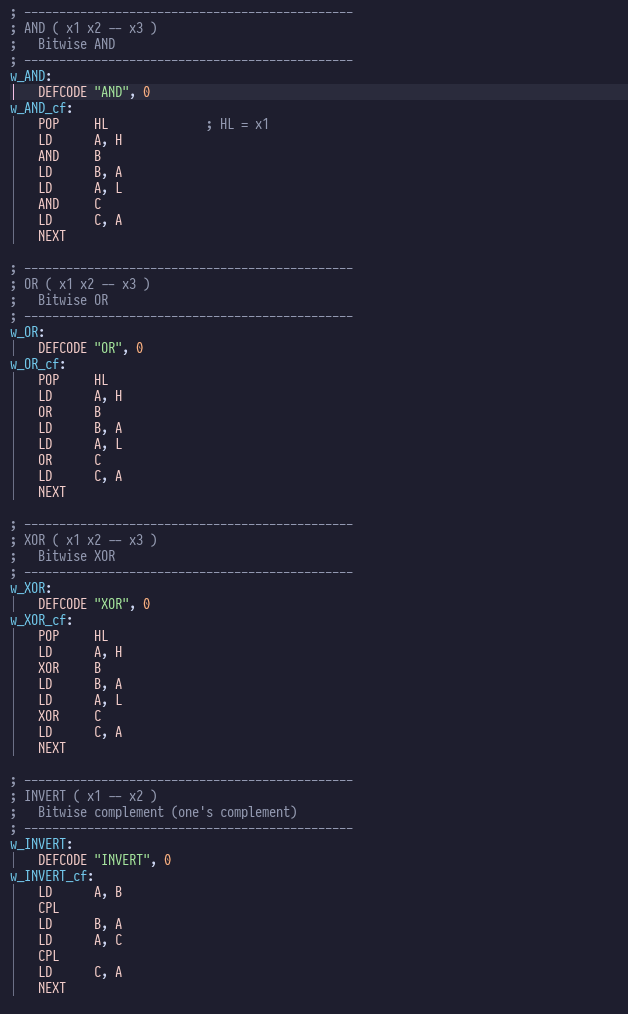
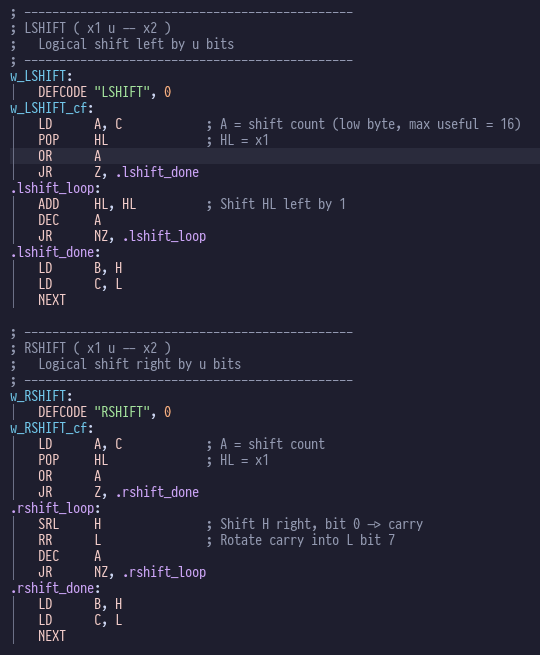
hare-brained projects were virtually nil. Generally you get bogged down in minutae like writing number conversion routines
or fast division routines that gets in the way of the fun stuff. Inevitably you are distracted by another idea, and break ground on
yet another new project, and the cycle continues!
But a capable LLM (Claude in my case) can write all the tedious stuff for you: you can pick and choose the fun bits that you want
to write yourself. Even the stuff you don’t write can teach you a lot, because you’ll be debugging it sooner or later.
Why are you blogging about it?
I’ve demo-d this approach to a couple of colleagues, with varying degrees of success. It isn’t a quick process, and being the human-in-the-loop
can consume many hours of precious development time. So I intend this blog to be a resource that BMAD neophytes can use to learn at their own
pace, assuming they have a passing interest in ancient computing languages and “tired iron”. You’ll get to see all the steps I took, warts
and all.
First steps
In the docs folder is an initial chat that I had with claude.ai, where we kicked some ideas around and I laid down a couple of
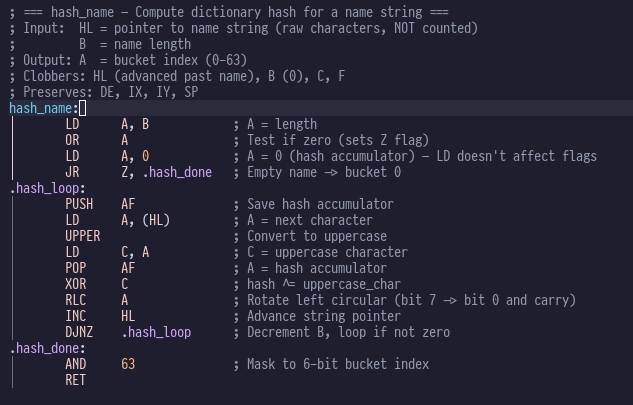
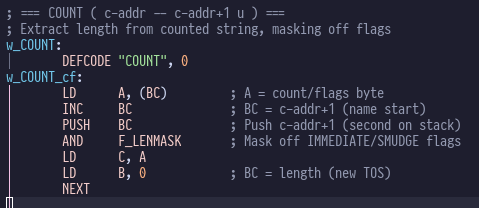
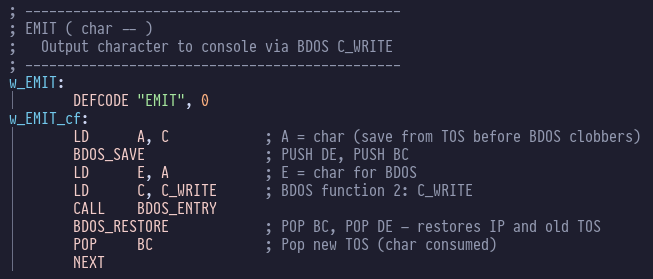
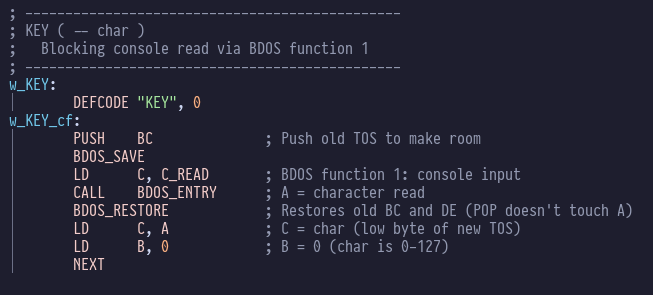
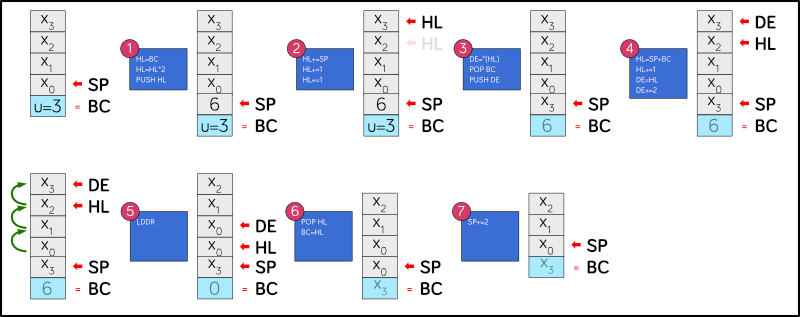
key concepts that I’d swiped from Moving Forth (direct threading, z80 register allocations). The hash table dictionary idea isn’t novel
either, I think I read that in one of the eForth books.
Next I created a new directory, git initd it, and installed BMAD with npx bmad-method install.
I copied the text of the chat, and used the command /bmad-create-product-brief to turn these vague noodlings into a coherent product brief.
In fact I don’t take the trouble to remember any bmad commands, I usually type a / and roughly what I’m after, and then pick from the
auto-complete suggestions, so here I probably typed /create picked /bmad-create-product-brief from the suggestions, and then added something
like create the brief from the conversation I had with claude in @docs/blah.md.
After answering a lot of questions, you get a brief document (_bmad-output/planning-artifacts/product-brief-antforth-2026-03-11.md).
As you can see, this is starting to look quite pro already.
The next step is /bmad-bmm-create-prd which will get a much more detailed document: a Product Requirements Document (or Project Requirements
Document, if you prefer). Again, you can see it in _bmad-output/planning-artifacts/prd.md. It can get a bit frothy and biz-devy, but it’s
worth sticking with it.
The next step is /bmad-bmm-create-architecture which is a lot more fun if you’re technical as you get to talk about compilers and assemblers
and stuff. This too nets you a new specification: _bmad-output/planning-artifacts/architecture.md.
All of these documents form a knowledge-base that will help inform future development. They’re not all included verbatim in each and every
development prompt, because that would eat your precious context space and leave little room for the actual development. Instead, as part of
the development cycle, a “planning” agent will pick and choose only the relevant parts of these documents to write an immediate plan for a
“development” agent who will do the actual work.
At any stage in the processes I have described so far, you have the option of “advanced solicitation” (even more questions for you to answer),
or “party mode”, which is often hilarious. Essentially you get multiple copies of your LLM role-playing developer, architect, QA, project
manager etc and they bicker about whatever the current topic is. If you are unsure about the path you’re taking, this can be hugely useful!
Frequently you can also yolo the rest which can be a time-saver if you know what you’re doing, but for your first couple of projects I’d
recommend going through the process yourself.
At this point I usually like to run /bmad-bmm-check-implementation-readiness which will catch any errors or omissions in the documents
we’ve generated so far.
Next it’s time to setup the planning with /bmad-bmm-sprint-planning then /bmad-bmm-create-epics-and-stories. These take a while (again)
and generate a lot of output that you are expected to read, and you should read it. The future quality of your project hinges on you
detecting errors or discrepancies during these initial stages.
Now we have an epics document (_bmad-output/planning-artifacts/epics.md) which gives us a high-level overview of the work to be done
(epics are “big stories”). We also have a plan in _bmad-output/implementation-artifacts/sprint-status.yaml which we can use to gauge
development progress. Typically you refer to this file often. Finally, we have the first story in _bmad-output/implementation-artifacts/1-1-project-scaffolding-and-build-toolchain.md and it’s this file that will guide the first development phase. It is always worth checking these scrupulously and pushing
back hard on anything you’re unhappy with, but we’ll leave that and the rest of the dev cycle for another time.
It made sense when you said it, but…
If you’re encouraged to try this yourself and it’s all a bit baffling, don’t worry. In the latest BMAD (v6) it is very difficult to go wrong.
If you try to execute a step out of order, agents will gently guide you back on track. If you don’t know what’s next, just ask in simple,
natural language.
One of the most important things to realise is that the built-in help /bmad-help i don't understand blah blah blah is fantastic - if
you’re in doubt, just ask it.
The Discord server is also very friendly and helpful.
Next time…
We will do some actual development!
]]>